
GLM stands for General Language Model – an advanced AI system designed to understand human language, generate text, perform reasoning, and handle a wide range of tasks such as translation, summarization, coding, and even multimodal analysis.
The latest and most sophisticated version in this series is GLM 4.5, developed by Zhipu AI. With enhanced accuracy, faster processing, and deeper contextual understanding, GLM 4.5 represents a significant leap forward in AI capabilities, enabling it to tackle both everyday and highly complex tasks with remarkable efficiency.
Read Also: How Kimi K2 Made Me Quit Claude Forever (OpenRouter)
Overview of GLM 4.5
Release Date: July 28, 2025
Zhipu AI officially unveiled the GLM 4.5 series on Monday, July 28, 2025, just after the World AI Conference in Shanghai.
Developer: Zhipu AI (also rebranded as Z.ai), based in Beijing, China.
Type: High-capability Large Language Model (LLM) with advanced Multimodal AI features.
License: Released under the MIT license, allowing full commercial use, self-hosting, and modification.
Variants in the GLM 4.5 Series
- GLM 4.5 – The flagship model with 355 billion total parameters (only 32 billion active per inference) using a Mixture-of-Experts (MoE) architecture. It balances deep reasoning with efficient computation.
- GLM 4.5-Air – A lightweight, faster sibling featuring 106 billion total parameters (12 billion active), optimized for environments with limited compute resources.
- GLM 4.5V – A vision-language multimodal model capable of understanding and reasoning across images, documents, videos, and text. It achieves state-of-the-art performance in versatile multimodal tasks and was introduced in August 2025.
Core & Key Features of GLM 4.5
- Massive Model Scale & Efficiency – The flagship GLM 4.5 boasts 355B total parameters, with only 32B active per inference through a Mixture-of-Experts (MoE) architecture. This design delivers top-tier reasoning power while keeping computational costs in check.
- Extended Context Handling – A 128K token context window allows the model to process extremely long documents, conversations, or codebases without losing context.
- Dual Reasoning Modes:
- Thinking Mode – Step-by-step reasoning for complex, high-accuracy tasks.
- Non-Thinking Mode – Faster, direct outputs for quick answers.
- Native Agent Abilities – Built-in support for advanced automation, including tool calling, web browsing, code execution, and SQL querying, enabling integration into intelligent-agent workflows.
- Benchmark Performance – Across 12 global evaluation benchmarks, GLM 4.5 scored 63.2 (3rd place worldwide), while the lighter GLM 4.5-Air scored 59.8 (6th place).
- Coding Expertise – Achieved a 53.9% win rate over Kimi K2 and 80.8% success against Qwen3-Coder in coding challenges, with 90.6% tool-calling accuracy, outperforming major rivals like Claude-4-Sonnet.
- Multilingual Mastery – High proficiency in languages including English, Chinese, Japanese, Korean, and more.
- Multimodal Intelligence (GLM 4.5V) – The GLM 4.5V variant, launched in August 2025, can understand and reason across images, documents, videos, charts, and GUIs, powered by Reinforcement Learning with Curriculum Sampling (RLCS).
- Open-Source Advantage – Released under the MIT license, GLM 4.5 is fully open-source and commercially usable, empowering developers, researchers, and organizations to self-host, modify, and deploy GPT-4–level AI without restrictions.
Read Also: Why Moonshot AI Kimi K2 is Breaking the Internet
Architecture Details
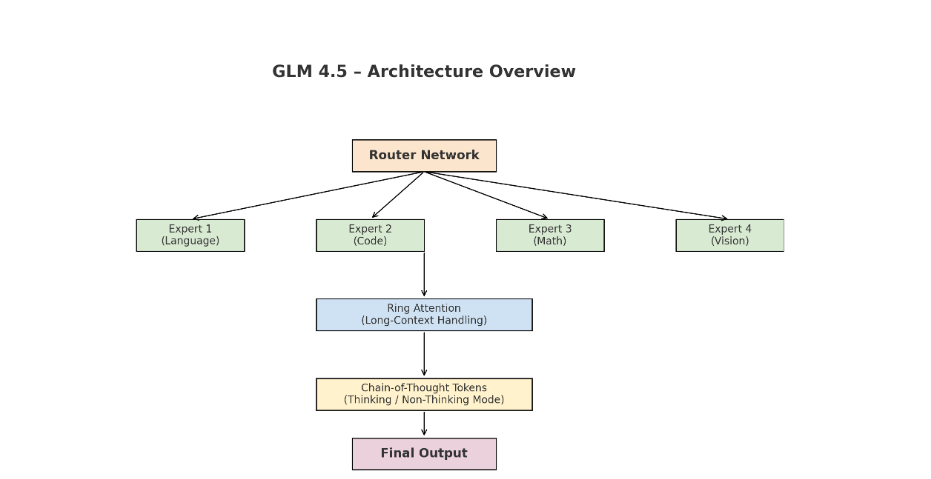
GLM 4.5’s performance leap isn’t just because of more parameters — it’s because of a clever blend of Mixture-of-Experts routing, long-context attention optimizations, and reasoning-oriented token handling. Let’s break it down.
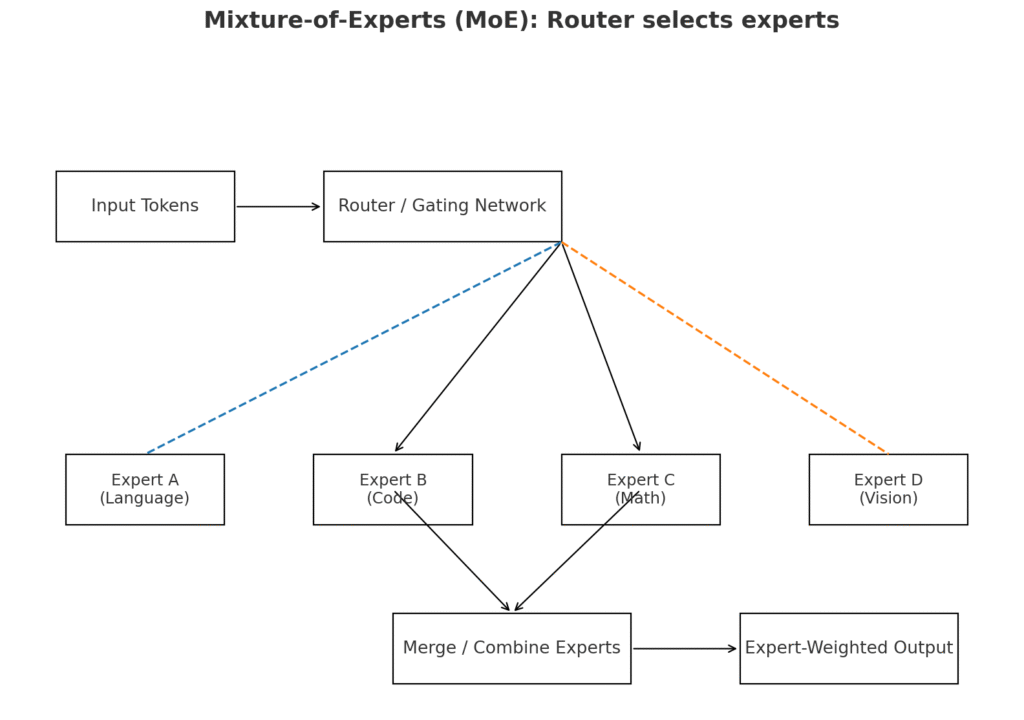
1. Mixture-of-Experts (MoE) – Power Without the Price Tag
Traditional large models activate all parameters for every single input, which is computationally expensive and slow.
GLM 4.5 takes a different path: it contains multiple “expert” neural networks inside one huge model, but activates only a few of them for each query.
- The Router Network:
At the heart of MoE is a router (or gating network). When you send a query, the router quickly analyzes it, predicts which experts are most capable of handling it, and forwards the data only to those experts. This means:- Light tasks get sent to smaller, faster experts.
- Complex reasoning gets routed to the heavyweight experts.
- The Payoff:
- 355B total parameters, but only 32B active per inference.
- Lower GPU load and faster inference compared to activating the full model.
- Precision when needed, efficiency when possible — a balance most models struggle to achieve.
Read Also: Grok Ani: The Future of AI Companions by xAI
2. Transformer Backbone Enhancements – Built for Long-Context Intelligence
The backbone of GLM 4.5 is still a Transformer, but heavily modified to handle very long sequences without choking the GPU.
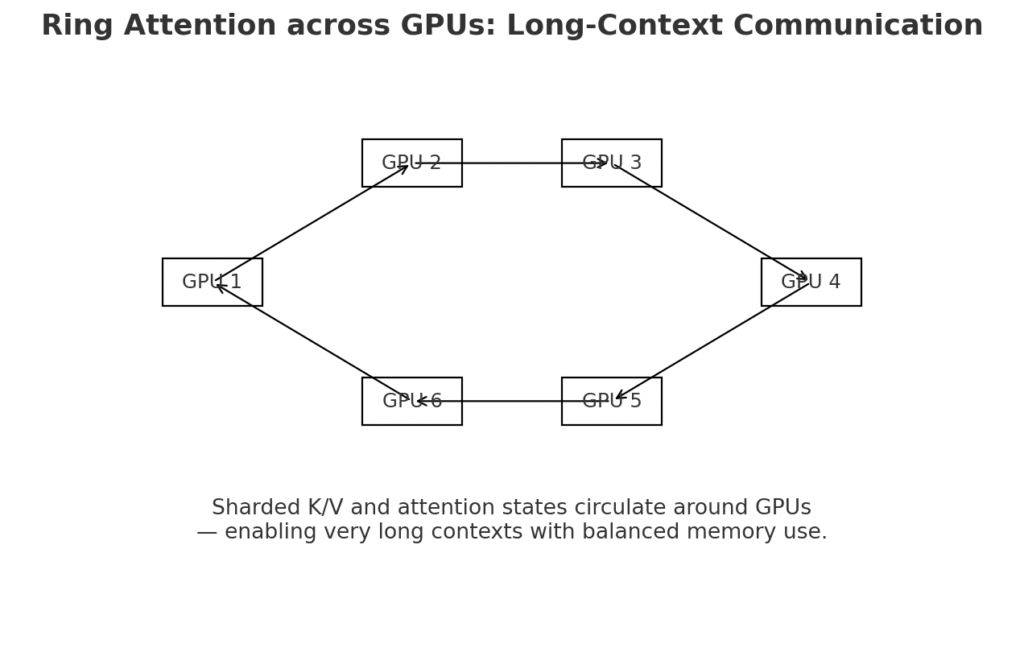
- Ring Attention:
- Standard attention mechanisms are memory-hungry. When you try to feed a model thousands of tokens, GPU memory usage explodes.
- Ring Attention spreads attention computation in a circular, peer-to-peer fashion across multiple GPUs.
- This drastically reduces memory bottlenecks, making 128K-token contexts possible without sacrificing stability.
- Dynamic Sparse Attention:
- Not every token is equally important in long inputs.
- Dynamic Sparse Attention selectively attends only to the most relevant tokens at each layer, cutting down redundant computations.
- This improves both speed and focus, especially for structured data like code or tabular content.
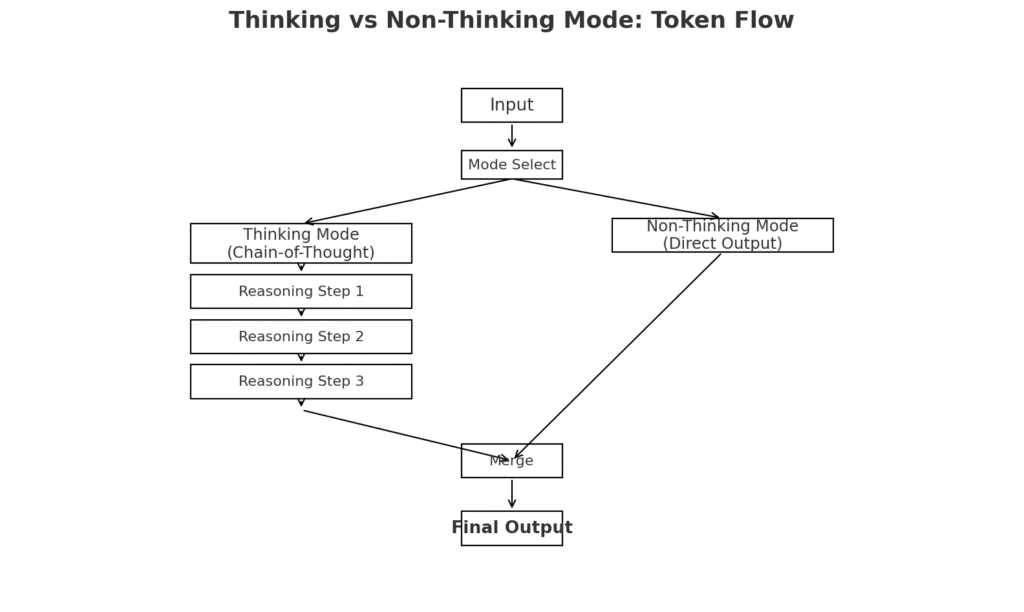
3. Chain-of-Thought (CoT) Tokens – Reasoning Like a Human
One of GLM 4.5’s unique strengths is its built-in reasoning mode, powered by Chain-of-Thought tokens.
- In Thinking Mode:
- The model generates internal reasoning steps before producing the final answer — almost like a mathematician writing notes in the margin before giving the solution.
- This step-by-step breakdown greatly improves accuracy in multi-step reasoning, mathematics, STEM problems, and logical analysis.
- In Non-Thinking Mode:
- The CoT process is skipped entirely, letting the model produce answers instantly when speed matters more than deep reasoning.
Why It Works So Well
By combining expert routing, optimized long-context attention, and adaptive reasoning tokens, GLM 4.5 manages to behave like a 355B-parameter super-intelligence when necessary, but runs with the cost of a 32B model most of the time.
This hybrid design is what allows it to compete with, and in some cases surpass, other frontier LLMs — while still being open-source under MIT.
Training Process
GLM 4.5’s training pipeline is designed to balance raw scale with fine-tuned intelligence, making it capable of advanced reasoning, coding, and multimodal understanding.
Hardware Infrastructure
- Trained on multi-thousand–GPU clusters using NVIDIA H800 accelerators, optimized for large-scale distributed training.
- High-bandwidth interconnects ensure fast communication between GPUs, essential for massive parameter models and Mixture-of-Experts (MoE) efficiency.
Training Stages
- Pretraining
- Ingests trillions of tokens from multilingual text, code, mathematics, and multimodal sources.
- Goal: Build broad linguistic, reasoning, and world-knowledge foundations.
- Supervised Fine-Tuning (SFT)
- Curated instruction–response pairs teach the model to follow user prompts with coherent, helpful outputs.
- Focus on diverse task types, from summarization to SQL queries.
- Reinforcement Learning from Human Feedback (RLHF)
- Human annotators rank multiple outputs to refine helpfulness, truthfulness, and safety.
- Aligns the model’s behavior with human preferences.
- Agent-Task Fine-Tuning
- Specialized training for tool usage, web browsing, code execution, and planning.
- Enhances agentic capabilities for autonomous workflows.
Data Sources
- Text & Knowledge: Wikipedia, academic books, news archives, multilingual corpora.
- Code: GitHub repositories across dozens of languages.
- Mathematics: Formal proof datasets and STEM problem banks.
- Multimodal: Image–text pairs, scanned PDF datasets, video frame captions.
GLM 4.5 Variants
| Model | Total Parameters | Active Parameters | Context Window | Specialization |
|---|---|---|---|---|
| GLM 4.5 | 355B | 32B | 128K tokens | Full-power reasoning & deep analysis |
| GLM 4.5-Air | 106B | 12B | 128K tokens | Lightweight, fast, low-resource deployment |
| GLM 4.5V | 106B | 12B | 128K tokens | Multimodal: vision, text, documents, videos |
Agent Capabilities
GLM 4.5 isn’t just a conversational model—it’s built to function as an autonomous AI agent, capable of interacting with tools, retrieving live data, and executing complex workflows.
Key Agent Skills
- Tool Calling
- Can call external APIs, interact with databases, and run Python scripts.
- Enables automation of data processing, analytics, and backend operations.
- Web Browsing
- Performs live internet searches, reads webpages, and extracts relevant information.
- Useful for research, fact-checking, and keeping outputs up to date.
- SQL Querying
- Directly interacts with SQL databases for data retrieval, updates, and analysis.
- Supports both simple and complex queries in structured environments.
- Multi-step Planning
- Breaks large goals into smaller, logical steps.
- Executes them in sequence, adjusting dynamically based on intermediate results.
- Memory Retention
- Stores important facts, preferences, and instructions across sessions.
- Useful for building personalized, persistent AI assistants.
Benchmarks
GLM 4.5 has been rigorously tested across diverse academic, coding, and agentic benchmarks, demonstrating strong reasoning, programming, and tool-usage abilities.
| Test | Score | What It Measures | Comment |
|---|---|---|---|
| AIME 2024 | 91% | Advanced mathematics problem solving | Elite-level math and logical reasoning |
| SWE-Bench Verified | 64.2% | Code understanding & bug fixing | Strong coding accuracy and debugging skill |
| TAU-Bench | 79.7% | Multi-step reasoning + tool usage | Well-balanced agentic reasoning |
| BrowseComp | 26.4% | Web search + live browsing task performance | Solid but with room for browsing optimization |
Ecosystem
GLM 4.5 comes with a rich ecosystem of tools and platforms, making it easy for developers, researchers, and businesses to integrate its capabilities into real-world workflows.
Core Components
- GLM-Agents
- A pre-built AI agent framework designed for automation, research, and task orchestration.
- Supports tool calling, web browsing, database querying, and multi-step workflows out of the box.
- GLM-Coder
- A fine-tuned version of GLM specialized for coding, debugging, and software development.
- Excels in multiple programming languages and integrates with IDEs for real-time assistance.
- GLM-Studio
- A web-based interface for chat, coding, and multimodal tasks.
- Offers an intuitive UI for experimenting with GLM 4.5’s full potential without heavy setup.
- Hugging Face Models
- Fully open-source model weights hosted on Hugging Face.
- Enables community-driven fine-tuning, deployment, and experimentation.
Strengths & Weaknesses
While GLM 4.5 is one of the most advanced open-source AI models available, it comes with its own trade-offs. Understanding both its advantages and limitations helps in choosing the right use case.
Strengths
- Open-source MIT License – Fully free for commercial use, modification, and self-hosting.
- Efficient High-End Reasoning – Thanks to the Mixture-of-Experts architecture, it delivers top-tier reasoning with lower GPU requirements than similarly powerful models.
- Multilingual Excellence – Strong in English, Chinese, Japanese, Korean, and other major languages, with competitive reasoning ability.
- Native Agent Integration – Built-in capabilities for tool calling, web browsing, SQL querying, and multi-step planning without external wrappers.
Weaknesses
- Slower in Thinking Mode – For simple or short queries, the step-by-step reasoning process can feel slower compared to direct-output models.
- Weaker in Rare Languages – Performance in less common languages still trails behind proprietary giants like Google Gemini.
- High VRAM Demand for Vision Model – The GLM 4.5V multimodal version requires around 48 GB of VRAM for optimal performance.
- Slightly Less Creative – Falls a bit short in imaginative writing compared to models like Claude 3.7.
Comparison with Other Models
| Feature | GLM 4.5 | GPT-4.5 Turbo | DeepSeek V3 | Claude 3.7 |
|---|---|---|---|---|
| License | MIT (open-source) | Closed | Closed | Closed |
| Context Window | 128K | 128K | 64K | 200K |
| Reasoning Strength | High | High | High | High |
| Tool/Agent Support | Native | Plugins / APIs | Native | Limited |
| Multimodal Support | Yes (GLM 4.5V) | Yes (GPT-4o) | No | No |
| Cost (self-host) | Low | High | High | High |
Deployment Options
GLM 4.5 offers flexibility in how it can be deployed, making it suitable for both high-performance and resource-limited environments.
- Local Deployment – The lightweight GLM 4.5-Air variant can run efficiently on a single high-end GPU such as the NVIDIA RTX 4090 or A100, making it accessible for developers without massive server infrastructure.
- Cloud Deployment – Full-scale models are available via Zhipu AI Cloud or third-party platforms like OpenRouter, allowing instant access without hardware management.
- On-Device / Edge Deployment – Quantized 4-bit or 8-bit versions reduce VRAM requirements, enabling the model to run on lower-end GPUs, workstations, or even certain edge devices.
Security & Privacy
GLM 4.5 includes multiple safeguards to ensure ethical use and protect user data:
- Safety Filters – Built-in moderation systems detect and block harmful, unsafe, or policy-violating outputs before they are returned to the user.
- Privacy Mode – In local deployments, the model can run entirely offline with no external API calls, ensuring sensitive data never leaves the host environment.
- RLHF Alignment – The model is fine-tuned with Reinforcement Learning from Human Feedback to encourage responsible and ethical responses while reducing bias and misuse risks.
Frequently Asked Questions
What does “open-source” mean for GLM 4.5?
Open-source means that the model’s weights and architecture are publicly available under the MIT license. This allows anyone to download, run, modify, and integrate GLM 4.5 into their own projects without paying licensing fees.
Can GLM 4.5 work without an internet connection?
Yes. If you run it locally, GLM 4.5 can function entirely offline, provided you have the necessary hardware. This makes it suitable for private or sensitive environments.
How does Mixture-of-Experts (MoE) help in performance?
MoE allows the model to “activate” only a subset of parameters for each task. This reduces computation costs while maintaining high reasoning accuracy, especially for complex queries.
Can GLM 4.5 be fine-tuned for industry-specific needs?
Absolutely. Developers can fine-tune the model using domain-specific datasets (e.g., medical, legal, financial) to improve accuracy for specialized tasks.
Is GLM 4.5 suitable for mobile or edge devices?
With quantization (e.g., 4-bit/8-bit versions), GLM 4.5 can be deployed on lower-VRAM GPUs and some edge devices, though performance will be reduced compared to full-scale cloud setups.
What kind of data was not used to train GLM 4.5?
The developers have stated that personal, private, or confidential user data was excluded from the training process to protect privacy.
How is GLM 4.5 different from traditional chatbots?
Traditional chatbots rely on scripted responses, while GLM 4.5 uses deep neural networks capable of reasoning, coding, and multimodal understanding—making it more adaptive and intelligent.






It’s great to see how Zhipu AI’s GLM 4.5 is pushing the boundaries of AI, especially with its MoE architecture. This allows for better scalability without sacrificing accuracy. I’m curious about how these improvements will affect the model’s real-world applications in fields like healthcare and finance.