
Stable Diffusion is an advanced open-source text-to-image AI model that generates high-quality images based on written prompts. Developed by Stability AI, it empowers users to create visuals purely through text, offering unmatched creative freedom without relying on centralized control.
By 2025, Stable Diffusion has significantly evolved—especially with the release of the Stable Diffusion 3.5 series. This version delivers more accurate, detailed, and customizable results, making it a go-to tool for both casual users and professional creators.
AI image generation now has a major creative and commercial impact across industries like:
- Graphic design
- Advertising and marketing
- Game development
- Concept art for films
- Educational content
Stable Diffusion stands out for its speed, output quality, and affordability. It’s not just a tool—it represents a shift in how we create, imagine, and interact with visual media.
How Did Stable Diffusion Emerge?
The development of Stable Diffusion was part of a broader movement where researchers and developers wanted AI image generation to be open and accessible — not just controlled by big tech companies.
By 2022, AI image tools had already gained popularity — with models like DALL·E (OpenAI), MidJourney, and Google Imagen making headlines. However, access to these tools was restricted through waitlists, private betas, or expensive subscriptions.
In this context, Stable Diffusion was launched as a fully open-source model, freely available for anyone to download, modify, and use.
Read Also: Kimi K2 AI
Who Developed Stable Diffusion?
Stable Diffusion was developed by Stability AI, a UK-based AI company founded by Emad Mostaque in 2020.
Key partners and contributors:
- Stability AI – Provided funding and led the model release
- CompVis (University of Heidelberg) – Conducted the core research and training
- LAION (Large-scale Artificial Intelligence Open Network) – Supplied the open dataset (LAION-5B) used to train the model
- Runway ML – Collaborated on the co-release and commercial integrations
What Was the Vision Behind Stable Diffusion?
Emad Mostaque and Stability AI had a clear vision:
“AI should be a public good.”
Their goal was to build a tool that could be used by artists, developers, educators, and hobbyists — without the barriers of licensing fees, usage restrictions, or surveillance.
Stable Diffusion became a symbol of open creativity, allowing anyone to generate high-quality art right from their own laptop — without needing permission from any corporate platform.
Today, Stable Diffusion is not just a model — it’s part of a broader AI movement focused on accessibility, openness, and creative freedom for everyone.
| Version | Release Date | Description |
|---|---|---|
| Stable Diffusion v1.4 | 22 August 2022 | First major public release. Made freely available on Hugging Face and GitHub. |
| Stable Diffusion v1.5 | 24 October 2022 | Improved version with better aesthetics and fine-tuned training. |
| Stable Diffusion 2.0 | 24 November 2022 | Introduced a new architecture, supported 768×768 resolution, used OpenCLIP. |
| Stable Diffusion 2.1 | 7 December 2022 | Enhanced prompt understanding and output quality. |
| Stable Diffusion XL (SDXL 0.9) | 26 April 2023 | Early release of SDXL with improved realism and style control. |
| Stable Diffusion XL (SDXL 1.0) | 26 July 2023 | Official SDXL launch with major quality improvements. |
| Stable Diffusion 3 (Preview) | 22 February 2024 | First public preview of SD3 with early multimodal features. |
| Stable Diffusion 3.5 | May–June 2025 (Expected) | Internal beta testing began in mid-2025. Official public release timelines vary by platform. |
If you’re referring to the very first public release, then:
🔹 Stable Diffusion v1.4 was officially launched on 22 August 2022.
This marked the beginning of the open-source AI art revolution, making high-quality image generation accessible to everyone.
Understanding Stable Diffusion
Stable Diffusion is a latent diffusion model that generates photorealistic or stylized images from simple text prompts. It translates words into visuals, turning your imagination into digital art.
How Does It Work?
- It works in a latent space, where images are compressed into a lower-dimensional form.
- The model adds noise to this representation and then denoises it to generate an image that matches the text input.
- It uses two key components:
- Variational AutoEncoder (VAE) – encodes and decodes image data.
- CLIP text encoder – converts your written prompt into a format the model understands.
Basic Use Cases
- Personal artwork and creative expression
- Social media visuals and digital posts
- Fun projects like fantasy characters, surreal landscapes, or sci-fi scenes
How to Get Started?
Online Platforms:
- stablediffusionweb.com: Free image generation, no signup required

- DreamStudio: Official platform by Stability AI with free credits and paid options
- Hugging Face Spaces: Try Stable Diffusion models for free or via API access
Local Setup:
- Use Hugging Face’s Diffusers library in Python to download the model
- Requires at least a 4GB VRAM GPU
- Tools like
AUTOMATIC1111/stable-diffusion-webuion GitHub offer a user-friendly interface
Mobile Apps:
- Stability AI’s mobile apps (beta in 2025) for iOS and Android, some with voice prompt features
API Access for Developers:
- Use services like RunPod, Replicate, or Stability AI’s official API to integrate image generation into your own apps or websites
Prompt Database in 2025
- Over 9 million user-generated prompts are available in the Stable Diffusion ecosystem
- Prompts are organized by category: photorealistic, anime, sci-fi, fantasy, abstract, and more
- You can search, remix, and reuse these prompts to create your own visuals
Example Prompt:
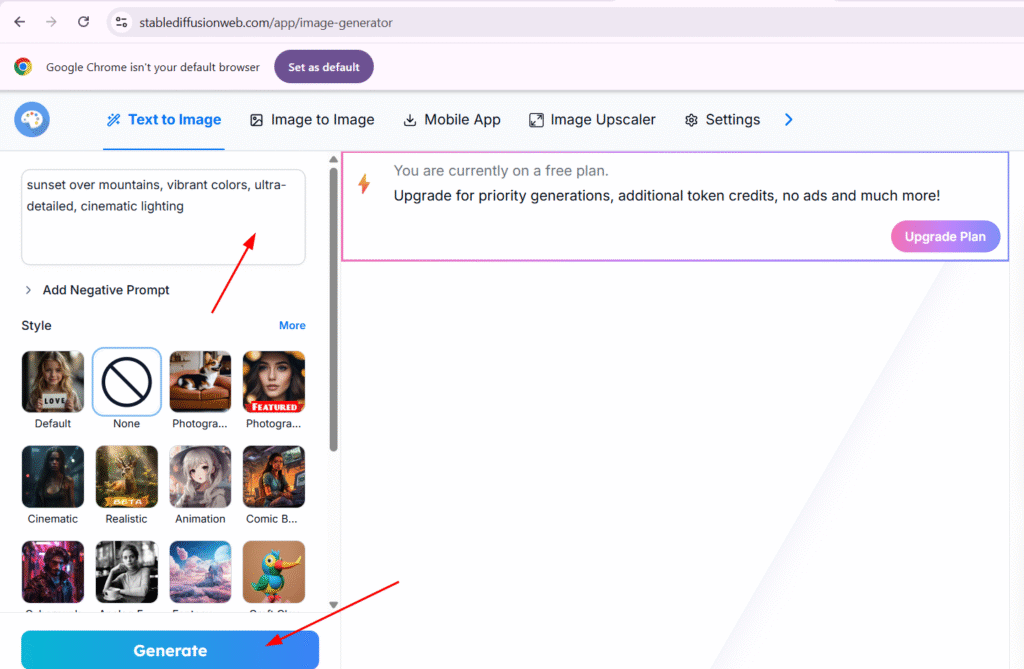
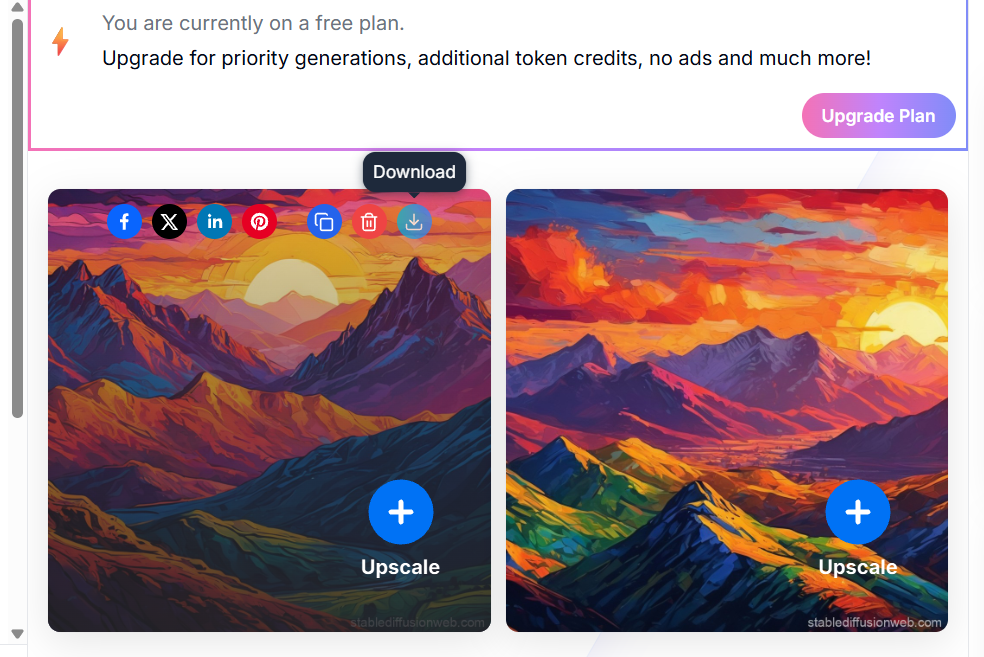
"sunset over mountains, vibrant colors, ultra-detailed, cinematic lighting"
Even a simple line like this can produce stunning, high-quality art.
Stable Diffusion makes AI image generation accessible to everyone, no technical background required.
Architecture of Stable Diffusion
Stable Diffusion, especially in its latest 3.x and 3.5 versions, continues to be built on a powerful and efficient latent diffusion architecture, which makes it possible to generate high-quality images from text descriptions using significantly less computing power than traditional image models.
Here are the key components that power Stable Diffusion in 2025:
1. Variational Autoencoder (VAE)
The VAE is used to compress and reconstruct images.
- The encoder converts a full-sized image (usually 512×512 pixels) into a compressed 64×64 latent space — a form that’s easier and faster to work with.
- The decoder takes that compressed latent representation and rebuilds it into a high-resolution image.
This process ensures faster generation and lower memory usage while maintaining visual fidelity.
2. Forward Diffusion Process
In training, every image is gradually turned into pure noise through forward diffusion.
- It works by adding Gaussian noise over several steps until the original image is no longer recognizable.
- This step helps the model learn how to generate images from scratch during the reverse process.
In practice, this phase is mainly used during training or image-to-image tasks, and is not directly involved in standard text-to-image generation.
3. Reverse Diffusion (Image Generation)
The reverse diffusion process is the core of image creation.
- Starting from random noise, the model iteratively removes noise step-by-step until a coherent image is formed.
- The process is guided by the text prompt, so the final image aligns with the user’s description.
In 2025 versions like SD 3.5, this denoising process is far more refined and prompt-aware, generating highly detailed, prompt-accurate results even for abstract or complex concepts.
4. Noise Predictor (U-Net with ResNet)
A specialized U-Net architecture is used to predict and remove noise at each step.
- Stable Diffusion uses a ResNet-enhanced U-Net, originally designed for image segmentation.
- The model looks at the noisy latent and estimates how much noise needs to be removed.
- This is repeated for several steps (often 20 to 50), depending on the quality setting.
The U-Net is also where prompt conditioning happens — it learns how to adjust the image generation based on what the user wrote.
5. Text Conditioning (CLIP + Transformer)
Text prompts are the main way users guide the image.
- A CLIP text encoder processes the input prompt and converts it into a vector format (up to 75 tokens).
- This embedding is passed into the model using a text transformer, which allows the U-Net to “understand” the prompt context.
In 2025, models like SDXL and SD3 have improved prompt conditioning with better handling of language nuances, style cues, and even multilingual support.
Additional Notes (2025 Enhancements)
- Users can set a random seed to generate different outputs from the same prompt.
- Newer versions also support image prompts, inpainting, outpainting, and multi-modal input (e.g., combining text + image + mask).
- The architecture is optimized for VRAM efficiency, now even running on some consumer-grade 4GB GPUs with reduced precision modes.
What Can Stable Diffusion Do in 2025?
By 2025, Stable Diffusion has evolved into one of the most versatile and accessible AI image-generation tools available. Unlike many heavy models that require cloud GPUs or advanced systems, Stable Diffusion runs efficiently—even on mid-range personal computers—and offers a wide range of creative capabilities:
Text-to-Image Generation
This remains the most popular use of Stable Diffusion.
- Just type a prompt like:
"a futuristic samurai standing on a neon-lit rooftop" - The model will generate a highly detailed image that reflects your description
- You can tweak the output by changing the seed, prompt, or denoising steps, giving you infinite creative possibilities.
Image-to-Image Generation
In this mode, you provide an existing image (like a rough sketch or photo) along with a prompt.
- Stable Diffusion will generate a new version of the image, guided by your input
- Ideal for artists who want to refine concepts, explore variations, or transform styles (e.g., turning a pencil sketch into an oil painting)
Artwork, Logos, and Digital Graphics
You can generate everything from digital paintings to modern logos using just text.
- Prompts can describe styles like “minimalist,” “grunge,” “cyberpunk,” or “flat design”
- Though the output is generative and unpredictable, combining text + image input + masking gives much more control in 2025
- Many freelancers and indie creators now use it for quick branding visuals
Image Editing and Inpainting
Stable Diffusion now supports powerful AI image editing tools.
- Simply upload a photo, mask the part you want to change (like erasing the background or an object), and write a new prompt
- It can be used for:
- Restoring old photos
- Removing or replacing objects
- Changing facial features or clothing
- Adding new elements to existing images
Advanced tools like AUTOMATIC1111, InvokeAI, and Krea AI Editor make this process extremely intuitive.
Video Generation and Animation
Thanks to integrations with tools like Deforum, ComfyUI, and AnimateDiff, Stable Diffusion can also help create short animations and video sequences:
- Animate a prompt across frames (e.g., “sunset slowly turns into night in a desert city”)
- Apply artistic styles to video clips
- Generate fluid motion effects like moving skies, rippling water, or camera zooms
Some creators even use Stable Diffusion in storyboarding, music videos, and motion design.
Features and Tools of Stable Diffusion
As of 2025, Stable Diffusion has evolved into a highly sophisticated and modular system capable of professional-grade image generation. With multiple model sizes, faster pipelines, and advanced features like ControlNet and Inpainting, it now caters to both everyday users and industry professionals.
Latest Models
1. Stable Diffusion 3.5 Large
- Size: 8.1 billion parameters
- Resolution: Native 1 Megapixel output
- Use Case: Built for professional and commercial work, such as marketing content, game concept art, and design mockups
- Strength: High fidelity, sharp details, and nuanced understanding of long prompts
2. Stable Diffusion 3.5 Large Turbo
- Specialty: Ultra-fast generation in as few as 4 steps
- Ideal For: Real-time applications, AI art demos, fast prototyping
- Trade-off: Slightly less detail than the full Large model, but much faster
3. Stable Diffusion 3.5 Medium
- Size: 2.5 billion parameters
- Optimized For: Consumer-level GPUs (4–8 GB VRAM)
- Benefit: Great balance of speed and quality for personal projects
Advanced Features
Inpainting
- Edit or replace specific parts of an image (e.g., change someone’s outfit, erase a background)
- Ideal for photo retouching, restoration, or creative manipulation
- Users mask the area and describe what they want to appear there
Outpainting
- Extend the canvas beyond its original borders
- Useful for turning a close-up into a wide scene or generating panoramic artwork
ControlNet
- Offers fine-grained control over the structure of the image using:
- Pose estimation
- Edge detection
- Depth maps
- Scribbles or outlines
- Allows for accurate replication of pose, structure, or shape from reference images
Depth2Img
- Generates new images based on a depth map, giving more control over spatial composition
- Useful for stylizing 3D scenes or generating alternate views of the same layout
Stable Cascade
- A multi-stage generation pipeline that improves image quality while reducing GPU usage
- Ideal for low VRAM devices (4GB and below)
- Generates high-quality images in a step-wise cascade, increasing resolution and detail over time
Prompt Engineering Tips
Crafting good prompts is still a key skill. Here’s how users are optimizing them in 2025:
Tips for Writing Effective Prompts
- Be specific and descriptive
- Use clear visual styles or artistic references
- Include details about lighting, mood, camera angle, and resolution
- Example:
"cyberpunk city at night, neon lights, wide-angle shot, dramatic lighting, 8k"
- Example:
Prompt Database Use
- Over 9 million prompts are now publicly shared across platforms like:
- PromptHero
- Lexica.art
- CivitAI
- Users often remix or evolve successful prompts for new results
Best Prompt Example (2025)
“A photorealistic portrait of a futuristic cyborg in a neon-lit cyberpunk city, cinematic lighting, highly detailed, 8k resolution, inspired by Blade Runner.”
- This kind of prompt is highly effective because it combines subject, style, setting, lighting, resolution, and even an artistic influence.
Most Popular Prompt Trends
Based on data from Reddit, ArtStation, and PromptHero, the most widely used prompt categories include:
- Photorealistic portraits
- Cyberpunk cities and characters
- Fantasy landscapes
- Historical reimaginings
- Anime-style scenes
Examples:
- “Renaissance-style portrait of an astronaut, starry background, reflective helmet.”
- “Majestic lion on a cliff at sunrise, golden light, savannah background.”
- “Japanese garden in autumn, impressionist style, koi pond with bridge.”
Hardware Requirements
Minimum Requirements:
- GPU: 4GB VRAM (NVIDIA GTX 1650, AMD RX 570, etc.)
- Can run SD 1.5 or SDXL (via Stable Cascade) at lower resolutions
Recommended for Full SD 3.5 Experience:
- NVIDIA RTX 4080/4090 with 16–24 GB VRAM
- Enables faster generation, higher batch sizes, and large-resolution outputs
Cloud Options:
- RunPod, iRender, AWS EC2, and Google Colab Pro+ offer scalable cloud GPUs for heavier models
Key Benefits of Stable Diffusion
| Feature | Description |
|---|---|
| Cost-Effective | Open-source, free to use; avoids expensive subscriptions like MidJourney or DALL·E |
| Customizable Outputs | Tools like Inpainting, ControlNet, Outpainting, and Depth2Img provide incredible flexibility |
| Fast Generation | Turbo models generate in 1–4 steps, making real-time use possible |
| Community-Driven | Active GitHub, Hugging Face, and Discord communities provide updates, tools, and extensions |
| Commercial Use | Most models/images fall under CC0 1.0 license, allowing free use even for commercial purposes |
| Privacy Friendly | Anonymous use supported by platforms like stablediffusionweb.com, no personal data tracking |
Technical and Practical Insights
Stable Diffusion 3.5 and its related models now use a more advanced architecture called the Multimodal Diffusion Transformer (MMDiT).
- Multimodal Diffusion Transformer (MMDiT): This allows better alignment between the input text and the generated image, improving accuracy and creativity.
- Cross-Attention Mechanism: It synchronizes the text and visual features, ensuring the model understands which parts of the prompt to emphasize in the image.
Stable Cascade
- Stable Cascade is a lighter and more memory-efficient version of SDXL.
- Designed for systems with limited GPU VRAM, it still produces high-quality images.
- Especially good for text-based visuals like logos, captions, or graphic design elements.
- Works on multi-stage generation (text → latent concept → image), which makes it scalable and efficient.
Integration and APIs
Stable Diffusion 3.5 models can be easily integrated into custom apps, websites, or production pipelines.
APIs and Libraries:
- Hugging Face Diffusers: Official support for easy model loading and generation.
- Stability AI APIs: Cloud-based APIs with commercial plans and GPU backends.
Local Setup:
- You can use Python frameworks like FastAPI or Flask to build your own local generation server.
- The
diffuserslibrary handles model inference and pipeline creation.
GUI Tools:
- AUTOMATIC1111 WebUI: A popular local interface for image generation with advanced features like ControlNet, inpainting, prompt history, and live previews.
Commercial Applications
Stable Diffusion is now powering a wide range of industries. Some major uses include:
1. Marketing
- Auto-generate social media graphics, product visuals, and promotional banners.
2. Game Development
- Use tools like Stable Fast 3D to generate 3D textures or concepts for characters and environments.
3. Film and Animation
- Create cinematic stills, environment art, and concept visuals with models like Juggernaut XL v9.
4. Immersive Media
- Convert 2D images into 3D-style motion clips using Stable Virtual Camera.
- Useful for virtual tours, educational content, and AR/VR applications.
Ethical and Legal Aspects
Copyright:
- Stable Diffusion outputs are released under the Creative Commons CC0 1.0 license, meaning they are free for commercial use.
- However, concerns remain around the LAION-5B dataset used to train many models.
- In mid-2025, a UK-based trial began over alleged unauthorized use of copyrighted images in LAION’s training data.
Ethics:
- Stability AI and third-party platforms now include filters and guidelines to avoid harmful or explicit content.
- Responsible usage is crucial to prevent abuse in deepfakes, misinformation, or unethical art reproduction.
Prompt Optimization Techniques
Prompt engineering remains key to getting the best results.
1. Keyword Weighting
- Format:
(keyword:weight) - Example:
(cyberpunk:1.5)gives more emphasis to the cyberpunk style in the image.
2. Negative Prompts
- Helps eliminate unwanted elements.
- Example:
"no blurry, no low-res"ensures the image is sharp and clean.
3. Effective Prompt Example
“A serene mountain landscape at sunrise, no buildings, no people, golden hour lighting, highly detailed.”
This tells the model what to include and what to avoid, leading to better, cleaner results.
Stable Diffusion vs. Other AI Image Generators
DALL·E 3 (by OpenAI)
- Pros:
- Very user-friendly and beginner-focused.
- High-quality image generation.
- Excellent at rendering text inside images (e.g., signs, logos).
- Cons:
- Closed-source: Not customizable or inspectable.
- Available only via ChatGPT Plus, which requires a paid subscription.
- Limited control over fine-tuning and edits.
- Stable Diffusion Advantage:
- Completely open-source.
- Can be used for free or at low cost.
- Offers advanced editing tools like ControlNet.
- Supported by a strong and growing community that releases regular updates.
MidJourney
- Pros:
- Known for its stunning, artistic, and stylistic outputs.
- Very accessible via Discord, with a simple command-based interface.
- Cons:
- Entirely paid; no free access.
- Limited customization — you can’t finely control small image details.
- No local installation or offline setup possible.
- Stable Diffusion Advantage:
- Can be used locally on your own system.
- Supports inpainting, outpainting, and prompt-based control.
- Offers deeper customization and reproducibility.
RunwayML
- Pros:
- Provides video generation tools and basic editing features.
- Designed for non-coders and creative professionals.
- Offers tools like Gen-2 for text-to-video.
- Cons:
- Free tier has heavy limitations.
- High costs for pro-level features or commercial use.
- Stable Diffusion Advantage:
- Free and open-source model with a wide variety of integrations.
- More cost-effective for heavy or frequent users.
- A broader and more active support community.
Why Stable Diffusion Is Often the Better Choice
- Open-Source
- Fully accessible and modifiable.
- Encourages innovation and transparency.
- Customizability
- Offers tools like inpainting, outpainting, ControlNet, and Stable Cascade.
- Tailored image generation for professional and hobbyist use.
- Flexibility
- Works both locally and on the cloud.
- Compatible with APIs, web UIs, and even some mobile apps.
- Cost-Effectiveness
- Can be run for free or very cheaply.
- No mandatory subscriptions or locked features.
- Strong Community Ecosystem
- Over 9 million prompts shared online.
- Ongoing community development, tutorials, and support across GitHub, Reddit, and Hugging Face.
Upcoming Developments
- Stable Video 4D 2.0
Expected to be a major upgrade in video generation, enabling high-fidelity 4D content (3D visuals over time). This version aims to produce more fluid, realistic, and cinematic animations — ideal for creative, gaming, and film industries. - Stable Audio Open Small
A lightweight audio model designed to run directly on consumer devices. It focuses on music and speech generation, pushing towards local, private, and real-time generative audio — perfect for mobile apps and edge devices.
Community Contributions
- Platforms like GitHub and Hugging Face play a central role in Stable Diffusion’s growth.
- Developers consistently contribute:
- Fine-tuned checkpoints
- Prompt-sharing tools
- Custom interfaces and APIs
- This open-source ecosystem ensures rapid innovation and decentralized progress — making Stable Diffusion more versatile with every release.
Broader Impact of AI Image Generation
- Art
- Expands creative possibilities for digital artists, graphic designers, and illustrators.
- Democratizes high-quality art production for individuals without formal training.
- Education
- Enhances visual learning with instantly generated diagrams, historical reconstructions, and storytelling aids.
- Encourages creativity and visual thinking among students.
- Entertainment
- Used in comics, films, animation, and gaming for rapid prototyping and visual design.
- AI-generated visuals can shorten production timelines and reduce costs.
Conclusion
Stable Diffusion isn’t just an AI tool — it’s a creative revolution. In 2025, it empowers users with open access, advanced features, and unmatched flexibility, making high-quality image generation truly accessible to all.
Frequently Asked Questions
Can Stable Diffusion work without an internet connection?
Yes, you can run Stable Diffusion locally on your device if your system meets the minimum GPU requirements. Tools like AUTOMATIC1111 WebUI or ComfyUI allow offline generation after initial setup.
Is Stable Diffusion safe for personal or professional use?
Stable Diffusion is generally safe, but users should be cautious with third-party models or websites. Always verify licenses and avoid generating harmful or copyrighted content.
Can Stable Diffusion generate consistent characters across multiple images?
Yes, with prompt tuning and tools like ControlNet or LoRA models, you can maintain visual consistency across a character series.
How do I fine-tune Stable Diffusion on my own dataset?
You can use DreamBooth, LoRA, or Textual Inversion techniques to train the model on your own images — helpful for personal branding, product design, or fan art.
Does Stable Diffusion support multi-language prompts?
Primarily, it works best with English prompts, but it can understand and generate images from simple prompts in other languages, depending on the tokenizer and model training.
What’s the difference between SD 1.5, SDXL, and SD 3.5?
SD 1.5: Lightweight, great for general use.
SDXL: Higher quality, better text understanding.
SD 3.5: Most advanced (as of 2025), includes faster generation, better realism, and improved structure in outputs.
Is Stable Diffusion allowed for commercial projects?
Yes. Images generated with most Stable Diffusion models are under the CC0 1.0 license, meaning you can use them commercially — though you should still avoid replicating trademarked or copyrighted content.
Can Stable Diffusion create images in a specific artist’s style?
Technically, yes — if prompted that way — but ethically and legally, using or mimicking living artists’ styles without consent is controversial and sometimes restricted on platforms.
How do I avoid generating NSFW content?
Use models with safety filters, avoid certain keywords, and include negative prompts like: "no nudity, no explicit, no suggestive" for safe results.
Can I animate characters generated with Stable Diffusion?
Yes. With Deforum, AnimateDiff, or Stable Video 4D (2025), you can create short animations or apply motion to static images generated by SD.
Leave a Comment